1. Introduction
In the physical realm, paper fiat currencies are almost impossible to duplicate. As a result, a spent US Dollar bill cannot be concurrently used by the same payor in a different transaction. In digital space, one could also rule out double spending occurrences by setting up a central arbiter. In this case, the central authority (e.g., a bank) would decide on the fate of a transaction and enforce consensus. However, such central arbiters do not exist in decentralized structures. Up until Bitcoin, all decentralized attempts suffered from the possibility of duplicating digital units and spending them more than once.
Any decentralized solution to the double spending problem requires the relevant participants to reach consensus and agree on the ordering of transactions. This will ensure the recording of when digital unit(s) of money were spent and invalidate any attempt by their previous owner to reuse them. Bitcoin’s innovation lies in its ability to offer such a solution even when a minority of participants may act maliciously. The elements of the Bitcoin Consensus (also known as the Nakamoto Consensus) span transactions, blocks and the blockchain. We will discuss them in a subsequent post. In this chapter, we introduce the problem of reaching consensus in distributed systems, of which the Bitcoin network is an instance.
In section 2, we provide a brief introduction to these systems and highlight the intimate bond between a consensus problem and the underlying system parameters. The set of relevant parameters typically includes the network topology, the nodes configuration, the reliability of the communication channel, the synchronicity model, the types of messages exchanged, the failure regime of nodes, and whether consensus is achieved in a deterministic or a randomized way.
In section 3, we discuss the classical Byzantine Generals Problem (BGP) introduced by Lamport et al. [5], [6]. The classical BGP result is easy to state but its proof is not necessarily straightforward. Given its importance and historical value, we revisit the proof in the hope of making it easier to follow. The Byzantine Generals Problem became an allegorical representation of that of reaching consensus in distributed systems. It is commonly stated that “Bitcoin solves the BGP”. However, Bitcoin’s consensus problem is defined on a system whose parameters differ from those of the classical BGP. We will revisit this in a subsequent post.
In section 4, we look at a different class of system models which includes fully asynchronous distributed systems over which consensus must be achieved deterministically. We state and prove the seminal result that such a consensus is impossible to achieve in the presence of even a single faulty node. This is known as the FLP impossibility result in reference to its authors Michael J. Fischer, Nancy Lynch, and Mike Paterson.
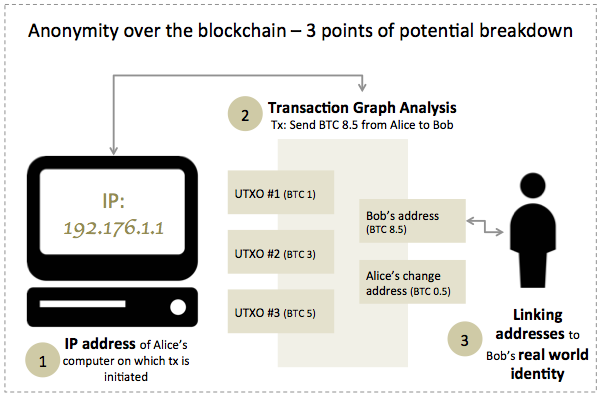
Read the rest of this entry » from Alice to Bob is an activity that ensures that the control over spending these Satoshis has moved from Alice to Bob who can now spend them (or a portion of them) at will. A Satoshi is the smallest transact-able unit of a bitcoin (the currency, also denoted BTC) and is equal to BTC
from Alice to Bob is an activity that ensures that the control over spending these Satoshis has moved from Alice to Bob who can now spend them (or a portion of them) at will. A Satoshi is the smallest transact-able unit of a bitcoin (the currency, also denoted BTC) and is equal to BTC  In light of this description, one can define a Bitcoin transaction as a data structure that essentially includes:
In light of this description, one can define a Bitcoin transaction as a data structure that essentially includes: of leading 0’s. The work associated with mining a given block corresponds to the value
of leading 0’s. The work associated with mining a given block corresponds to the value  where
where  0.00167 blocks / second (i.e., 1 block per 10 minutes). We discuss PoW as well as other consensus protocols in more details in another post.
0.00167 blocks / second (i.e., 1 block per 10 minutes). We discuss PoW as well as other consensus protocols in more details in another post. This a very large prime number that serves as the order of the underlying field
This a very large prime number that serves as the order of the underlying field 
 where
where

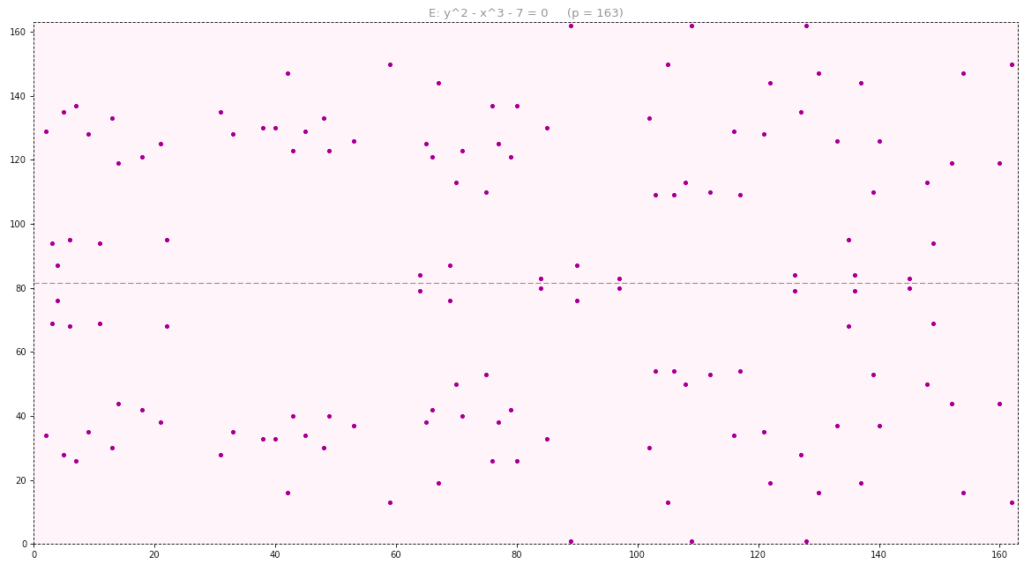
 denotes the point at infinity and is the identity element of the group. Here is a euclidean representation of this curve when
denotes the point at infinity and is the identity element of the group. Here is a euclidean representation of this curve when  (it is not feasible to show it for
(it is not feasible to show it for  ).
).
 has abscissa and ordinate given by
has abscissa and ordinate given by





 79BE667E F9DCBBAC 55A06295 CE870B07 029BFCDB 2DCE28D9 59F2815B 16F81798
79BE667E F9DCBBAC 55A06295 CE870B07 029BFCDB 2DCE28D9 59F2815B 16F81798 483ADA77 26A3C465 5DA4FBFC 0E1108A8 FD17B448 A6855419 9C47D08F FB10D4B8
483ADA77 26A3C465 5DA4FBFC 0E1108A8 FD17B448 A6855419 9C47D08F FB10D4B8


 denotes the order of
denotes the order of  and must divide
and must divide  i.e., the order of
i.e., the order of  . The cofactor
. The cofactor  is equal to
is equal to  which in this case is equal to 1. That means that the order of
which in this case is equal to 1. That means that the order of  i.e.,
i.e.,  Since
Since  is a cyclic group and any of its elements could serve as a generator.
is a cyclic group and any of its elements could serve as a generator. is a 256-bit long scalar chosen from the set
is a 256-bit long scalar chosen from the set

 is an element of the subgroup
is an element of the subgroup 
 More specifically,
More specifically,
 (
( It is an element of the set
It is an element of the set  which in this case is equivalent to
which in this case is equivalent to  Both
Both  and
and  are 256-bit long.
are 256-bit long.