
1. Introduction
In the physical realm, paper fiat currencies are almost impossible to duplicate. As a result, a spent US Dollar bill cannot be concurrently used by the same payor in a different transaction. In digital space, one could also rule out double spending occurrences by setting up a central arbiter. In this case, the central authority (e.g., a bank) would decide on the fate of a transaction and enforce consensus. However, such central arbiters do not exist in decentralized structures. Up until Bitcoin, all decentralized attempts suffered from the possibility of duplicating digital units and spending them more than once.
Any decentralized solution to the double spending problem requires the relevant participants to reach consensus and agree on the ordering of transactions. This will ensure the recording of when digital unit(s) of money were spent and invalidate any attempt by their previous owner to reuse them. Bitcoin’s innovation lies in its ability to offer such a solution even when a minority of participants may act maliciously. The elements of the Bitcoin Consensus (also known as the Nakamoto Consensus) span transactions, blocks and the blockchain. We will discuss them in a subsequent post. In this chapter, we introduce the problem of reaching consensus in distributed systems, of which the Bitcoin network is an instance.
In section 2, we provide a brief introduction to these systems and highlight the intimate bond between a consensus problem and the underlying system parameters. The set of relevant parameters typically includes the network topology, the nodes configuration, the reliability of the communication channel, the synchronicity model, the types of messages exchanged, the failure regime of nodes, and whether consensus is achieved in a deterministic or a randomized way.
In section 3, we discuss the classical Byzantine Generals Problem (BGP) introduced by Lamport et al. [5], [6]. The classical BGP result is easy to state but its proof is not necessarily straightforward. Given its importance and historical value, we revisit the proof in the hope of making it easier to follow. The Byzantine Generals Problem became an allegorical representation of that of reaching consensus in distributed systems. It is commonly stated that “Bitcoin solves the BGP”. However, Bitcoin’s consensus problem is defined on a system whose parameters differ from those of the classical BGP. We will revisit this in a subsequent post.
In section 4, we look at a different class of system models which includes fully asynchronous distributed systems over which consensus must be achieved deterministically. We state and prove the seminal result that such a consensus is impossible to achieve in the presence of even a single faulty node. This is known as the FLP impossibility result in reference to its authors Michael J. Fischer, Nancy Lynch, and Mike Paterson.
2. Distributed systems
We define a distributed system to be a set of nodes spread-out across space. Each node runs a distinct process and can communicate with other nodes. For all practical matters, one can think of a node as a separate computer and the act of running-a-process as that of executing a specific task or computation. Moreover, a client that uses the distributed system does not perceive its nodes as separate entities but rather as part of a unit. In this unit, processes are executed in order to achieve a common purpose.
It is conceivable for a given node to run a process while at the same time be in control of its rules of execution (e.g., mandate when to run a process). In general however, one cannot necessarily assume that execution and governance (i.e., the particular model of control or ownership) are carried out by the same entity. A centralized governance is one where the ruling over the system is concentrated (e.g., in an individual, an organization, a state). On the other hand, the ruling in a decentralized system is spread over multiple entities.
An important implication is that a distributed system can be centralized. For example, Facebook runs a centralized model where decision-making power is concentrated within the organization. It remains nevertheless a distributed system where different servers and computers implement different processes. Bitcoin on the other hand, is an example of a distributed system that is also decentralized for anyone can join or leave the network and run an independent node.
In what follows, we describe some of the merits of distributed systems. We also showcase the importance of reaching agreement in such structures and highlight some of the challenges of doing so in the presence of faults. We finally introduce the notion of consensus and the parameters that characterize its associated system model.
The merits of a distributed system – In order to better appreciate the value of a distributed system, we mention three of its potential advantages over its non-distributed counterpart:
- Better scaling: In a scenario where a particular node receives excessive traffic, there may be a threshold beyond which the node’s performance becomes noticeably impacted. One could upgrade the processing power of the node but the merits of this vertical scaling are bound to reach a limit. A more suitable alternative would be to distribute the workload by adding more nodes to the system.
- Higher resilience: In a single-node system, any failure could be severely damaging. In order to mitigate the risk of a single-point failure and increase the level of tolerance for faulty behavior, one can create more redundancy by adding more nodes.
- Lower latency: If the system’s clients were spread across the globe, information would have to travel for longer distances resulting in longer latencies. This can be improved by geographically distributing a richer set of nodes.
The need for agreement in a distributed system – In a distributed system where different nodes run their own processes, communicate with each other, and alter their perceptions of the state of the system accordingly, these nodes may end up having different concurrent views of the system. The need to agree on a common view is imperative in certain cases as highlighted by the following examples:
1) The distributed Transaction-Commit problem: A transaction gets divided into processes run by different nodes. The objective is to decide whether or not to commit the transaction to a given database. The important consideration is that if any node rejects it, then all nodes must do so too. Otherwise, the system’s view will be inconsistent as some nodes agree to include it while others don’t. A commitment of the transaction must occur if and only if all relevant nodes agree to do so.
2) State Machine Replication (SMR) systems: A state machine reflects the state of a system at a given point in time. It takes a set of inputs or commands, performs a set of operations (collectively defining a transition function), and then computes an output used to update the state of the system. An SMR distributed system consists of various nodes that are all supposed to run the same transition function. In order to ensure a consistent view of the system’s state, there needs to be agreement on the inputs to the transition function i.e., the current state of the system as well as inputs used to alter it.
A client may send a number of sequential requests to an SMR system. The ordering of these requests is paramount and any two nodes executing them out of order will have two conflicting views of the state of the system. This is known as the log replication problem (it is a reference to the idea that the sequence of commands is stored in a log). Assuming that all nodes operate the same deterministic transition function, an agreement in this context corresponds to an alignment among all nodes on the sequencing of the commands.
One important example of an SMR is the Bitcoin ledger. The state of the system at a given time corresponds to the set of Unspent Transaction Outputs (UTXO) (the reader can refer to Bitcoin Transactions (pre-segwit) for an introduction to UTXOs). Simply stated, this set corresponds to all public keys holding unspent satoshis. Inputs that alter the state of the ledger consist of valid Bitcoin transactions. Transactions however must be executed in a well-defined sequence agreed upon by all nodes. Otherwise, a Bitcoin transaction considered as valid by one node could be invalidated by another. We will discuss the building blocks and details of the Bitcoin consensus protocol in a later post.
3) Clock synchronization: In order for a system’s nodes to execute certain processes in a well-defined order, they need to share a common view of time. The challenge is that the internal clocks of nodes differ in the way they count the passage of time. The difference is due to clock drift, usually caused by relativistic effects. Clock synchronization is the problem of coordinating the clocks of various nodes at regular time intervals to ensure ordered execution of events. This problem can be equivalently stated as one of reaching agreement on a common value of time between various nodes.
The challenge of reaching agreement in the presence of faults – In light of the above examples, it becomes clear that some distributed systems must ensure that their nodes reach agreement. In a perfect world where nodes relay information truthfully, agreement could be easily achieved. For example, each node could be requested to relay its information to peers and then have all nodes apply a common function. Nodes however, may not be truthful all the time. In general, one assumes that a certain maximal number of them can be faulty. The behavior of faulty nodes is specified by a pre-defined failure model which may consist of:
- Crash failure: In this model, a node can either be fully operational or out of order. In particular, a node may fail in the middle of an execution. As a result, it could have sent information to only a small subset of its peers before crashing.
- Omission failure: Information sent by a node may not be received by a peer. This can be due to various factors including transmission problems or buffer overflow.
- Byzantine failure: Byzantine faults are the weakest form of failures in the sense that faulty nodes can behave arbitrarily without abiding by specific constraints. In a byzantine regime, a faulty node can act maliciously vis-a-vis one of its peers at a certain time instance and honestly at another. In this context, malicious behavior is to be understood in its general form including e.g., communicating wrong information to peers or abstaining from sending or relaying any information. These faults are particularly important in a decentralized setting.
Consensus in distributed systems – The real challenge with distributed systems is to reach agreement in the presence of faulty behavior. More formally, the act of reaching agreement is encapsulated in the notion of achieving consensus. An algorithm is said to achieve consensus in a distributed system if it guarantees that the following three criteria are met:
- Agreement: All non-faulty nodes (also known as correct nodes) must agree on the value (or array of values) that they compute. In other words they must all share the same value(s) after the algorithm is executed.
- Validity: In the absence of any constraint, non-faulty nodes could agree on trivial values irrespective of the nature of the problem. In order for them to be meaningful, agreed-upon values must satisfy more stringent constraints. The validity criterion ensures that non-faulty nodes decide on “acceptable” value(s) for some notion of “acceptable”. Different validity requirements lead to different types of consensus.
- Termination: All non-faulty nodes must eventually decide on a value (or array of values).
The above consensus criteria are usually expressed in terms of safety and liveness properties. Informally, safety is a property that must be continuously observed by the system in order to ensure that no “bad” outcome occurs. Liveness on the other hand, guarantees that a “good” outcome will eventually take place. Liveness properties do not need to be continuously observed but must eventually be met:
- The Agreement criterion ensures that non-faulty nodes never diverge in their decision making. It is thus considered a safety property.
- The Validity criterion guarantees that non-faulty nodes never choose an inadequate value. As a result, it is also considered a safety property.
- The Termination criterion on the other hand, guarantees that eventually every non-faulty node will decide on a value. It is hence a liveness property.
The aforementioned Termination criterion requires that for each and every iteration of the consensus algorithm, non-faulty nodes decide on a value (or array of values). This definition characterizes a class of consensus algorithms known as deterministic. Termination could also be defined stochastically, leading to the class of randomized consensus algorithms. In this case, it becomes:
- Termination: All non-faulty nodes must eventually decide on a value (or array of values) with probability 1.
In other words, some executions of the algorithm may fail to terminate as long as the probability of it happening approaches 0 when the number of executions tends to infinity.
System model specification – The characterization of a distributed system requires specifying a number of system parameters. They include:
- Nodes configuration: A system may consist of a pre-defined set of static nodes that never changes over the course of execution. For instance, nodes could be geographically spread servers deployed by an organization to service its global client base. Configurations could also be dynamic (e.g., Bitcoin) with different nodes joining or leaving at various points in time.
- Network topology: Nodes may be connected in various ways. For instance, a node can be linked to a select set of peers or to every other node as part of a complete graph topology.
- Communication channel reliability: In addition to specifying the failure regime of nodes, a full description of a distributed system requires defining the reliability of its underlying communication channel. For all practical purposes, we will assume that the infrastructure is reliable and limit faulty behavior to nodes.
- Communication delay: A system can be classified as synchronous, partially synchronous or fully asynchronous. In a synchronous network, messages sent are guaranteed to be delivered to peers within a fixed delay of
 seconds known a priori. This presupposes that nodes have a common reference time against which is measured and is typically achieved through clock synchronization at regular intervals called rounds. One advantage of synchronous systems is that nodes can recognize if a message has not been sent by waiting seconds from the beginning of a specific round.
seconds known a priori. This presupposes that nodes have a common reference time against which is measured and is typically achieved through clock synchronization at regular intervals called rounds. One advantage of synchronous systems is that nodes can recognize if a message has not been sent by waiting seconds from the beginning of a specific round.A more realistic model is that of an asynchronous network where no guarantees are imposed on message delivery delay except for the assurance that messages sent will eventually be delivered. Contrary to the synchronous case, asynchronous networks do not rely on a notion of a common reference time. An important result in distributed systems theory is the impossibility of achieving deterministic consensus in a fault-tolerant asynchronous setting. This is the FTP impossibility result [4] that we will discuss in section 3. The result ceases to hold if the deterministic constraint is replaced by its randomized counterpart [1], underscoring as such the importance of specifying the system parameters prior to solving for consensus.
A model that lies midway between these two extremes, is the partially synchronous one [2]. Partial synchrony comes in different flavors. One version assumes the existence of a not known a priori upper-bound on the delay to deliver a message from one node to a peer. Another version assumes that the bound is known a priori but only guaranteed to apply starting at an unknown time instance. - Message authentication: Two types of messages could affect the process of reaching consensus in distributed systems. Unauthenticated or oral messages can be tampered with. A malicious node could modify the content of a message it received before it relays the altered version to a peer. It could also create a message and claim that it received it from a peer. Authenticated or signed messages on the other hand, are tamper-proof and forgery attempts will be detected with overwhelming probability. As a result, solving for consensus with signed messages is generally easier because the arsenal of malicious weapons does not include forgery.
In summary, consensus in distributed systems depends on a number of parameters. In order to specify a consensus problem, one needs to define:
- The system parameters including the nodes configuration and topology, reliability of the channel, synchronicity model, and types of messages.
- The faulty nodes failure regime (e.g., byzantine).
- The nature of the Termination criterion (i.e., deterministic or randomized).
- The consensus problem as defined by the relevant validity criterion.
3. The classical Byzantine Generals Problem
The Byzantine Generals Problem (BGP) introduced by Lamport et al. in 1982 [5] describes how a distributed system can operate effectively even if some nodes fail under a byzantine fault regime. It portrays the system as an army whose generals need to agree on a common action plan (e.g., attack or withdraw) and where some may be traitors, sending conflicting messages to peers. In essence, the BGP is an allegorical representation of the problem of reaching consensus in distributed systems and is defined as follows:
1) System parameters:
- Nodes configuration: The system consists of a set
 of
of  pre-defined and static nodes (i.e., addition or removal of nodes is not allowed). Each node has a device (e.g., a sensor) that runs a process
pre-defined and static nodes (i.e., addition or removal of nodes is not allowed). Each node has a device (e.g., a sensor) that runs a process  (e.g., a sensor measurement) and computes a private value
(e.g., a sensor measurement) and computes a private value  (e.g., a reading from sensor measurement).
(e.g., a reading from sensor measurement). - Network topology: The network is modeled as a complete communication digraph
 with nodes, where each two nodes are linked by a bidirectional communication channel or edge.
with nodes, where each two nodes are linked by a bidirectional communication channel or edge. - Communication channel reliability: The edges in are assumed to be fail-safe i.e., truthful with no error in communication.
- Communication delay: The edges in exhibit negligible communication delay. More importantly, the network is assumed to be synchronous.
- Message authentication: Messages are assumed to be unauthenticated but the identity of the sender is always known to the receiver. Note that in [5], the authors also consider a variant of the problem with signed messages instead.
2) Failure regime: Although the communication channel over is assumed to be fail-safe, a subset of may be faulty. We assume that at most  out of the nodes could be faulty under a byzantine failure regime.
out of the nodes could be faulty under a byzantine failure regime.
3) Termination criterion: The model assumes a deterministic termination rule.
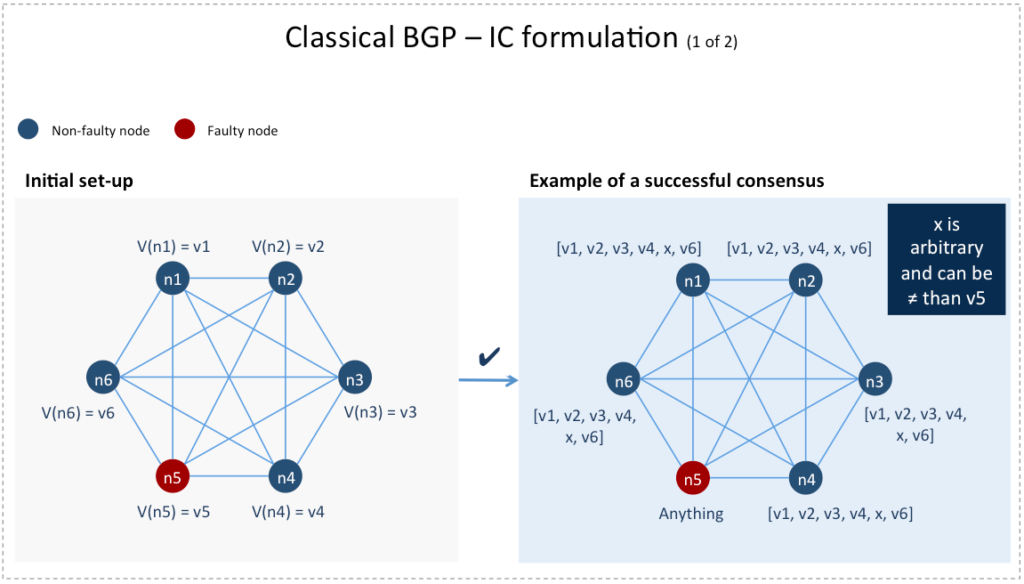
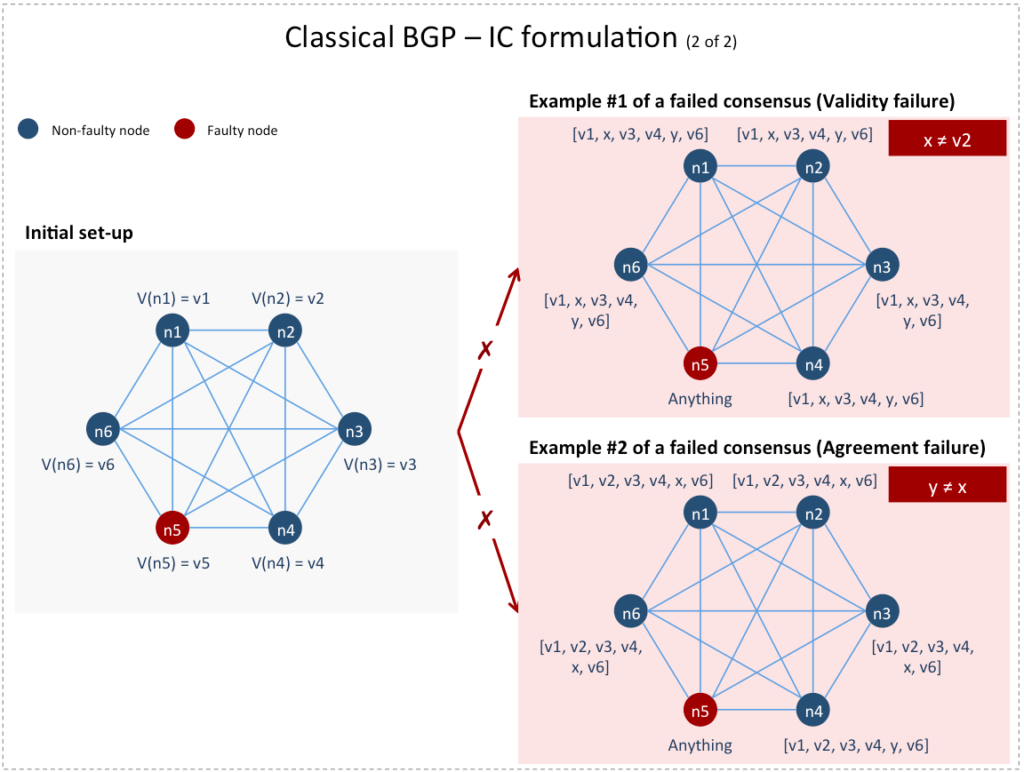
4) Agreement and validity criteria: Each non-faulty node in computes an –vector whose  entry is a value it calculates for the node such that:
entry is a value it calculates for the node such that:
- Agreement: All non-faulty nodes compute the same -vector
![A = [v_{1}, .., v_{n}].](https://delfr.com/wp-content/ql-cache/quicklatex.com-a6059fd68a9ec45988ab8a0248271115_l3.png "Rendered by QuickLaTeX.com")
- Validity: If node
 is non-faulty and its private value is
is non-faulty and its private value is  then the entry of
then the entry of  computed by all non-faulty nodes is
computed by all non-faulty nodes is  . In other words,
. In other words, 
These consensus criteria are known as the Interactive Consistency (IC) formulation of the classical BGP [6]. Note that they do not require specifying which nodes are faulty. Furthermore, the elements of corresponding to faulty nodes may be arbitrary.
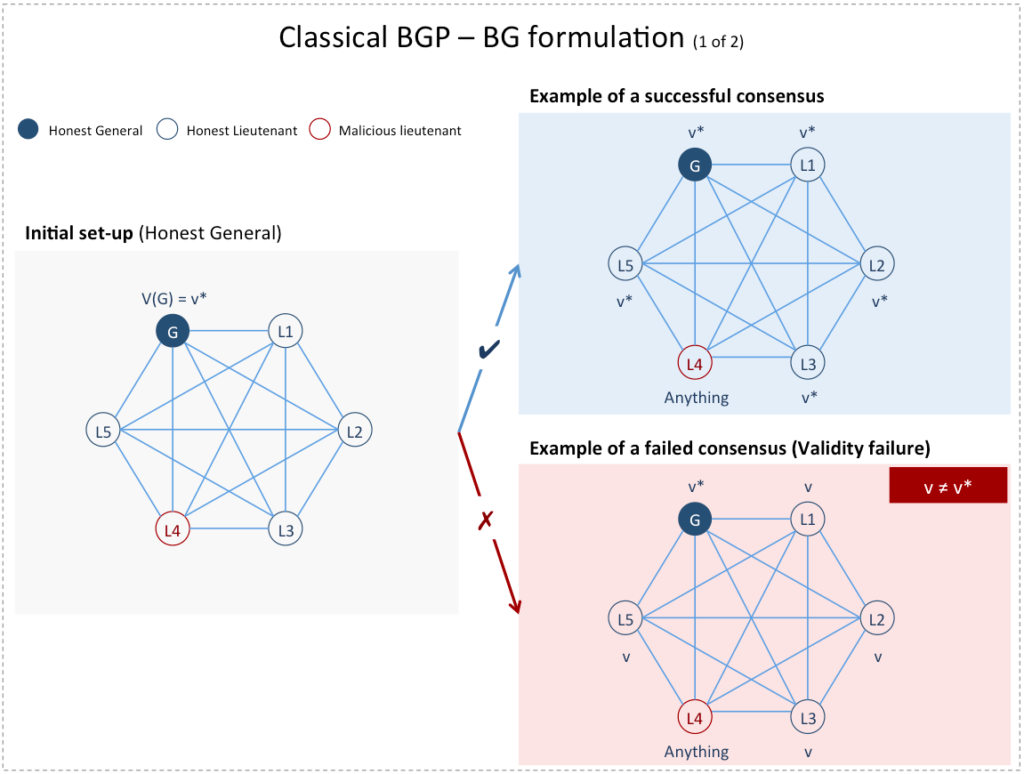
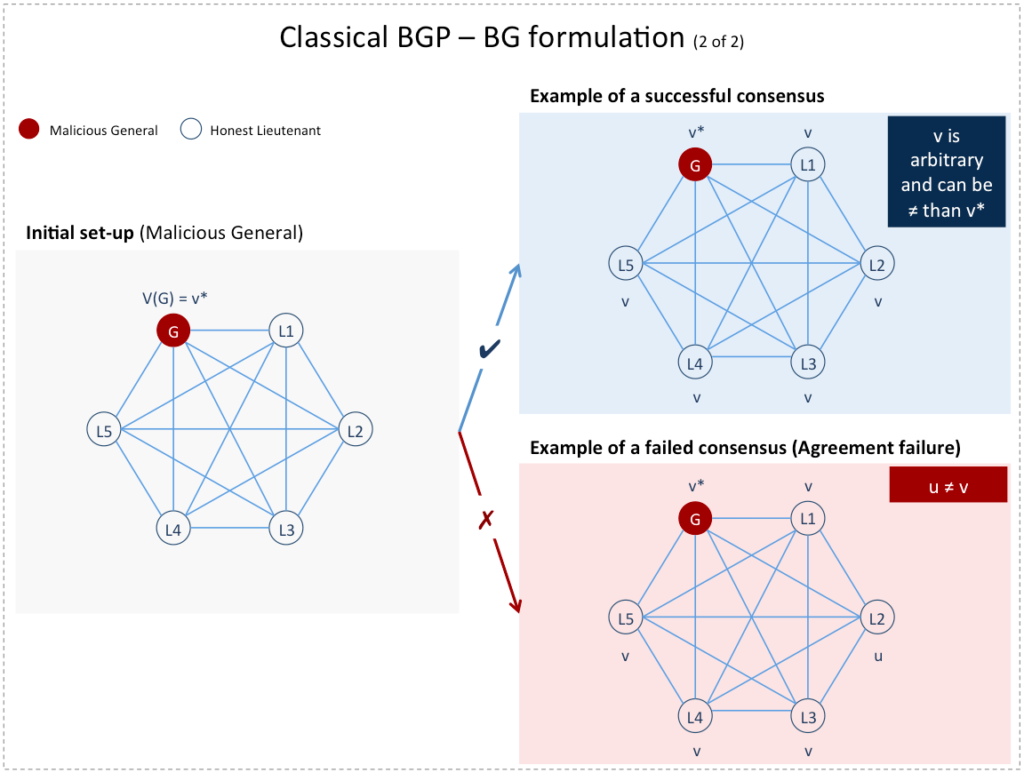
It turns out that the (IC) formulation can be equivalently expressed in two other ways: A Byzantine Generals (BG) formulation and a Consensus (C) one. The (BG) formulation introduced in [5] states that a General in the Byzantine army must send a value  to his lieutenants such that:
to his lieutenants such that:
- Agreement: Honest lieutenants (i.e., non-faulty nodes) agree on a value

- Validity: If the General is honest (i.e., source node is non-faulty), then

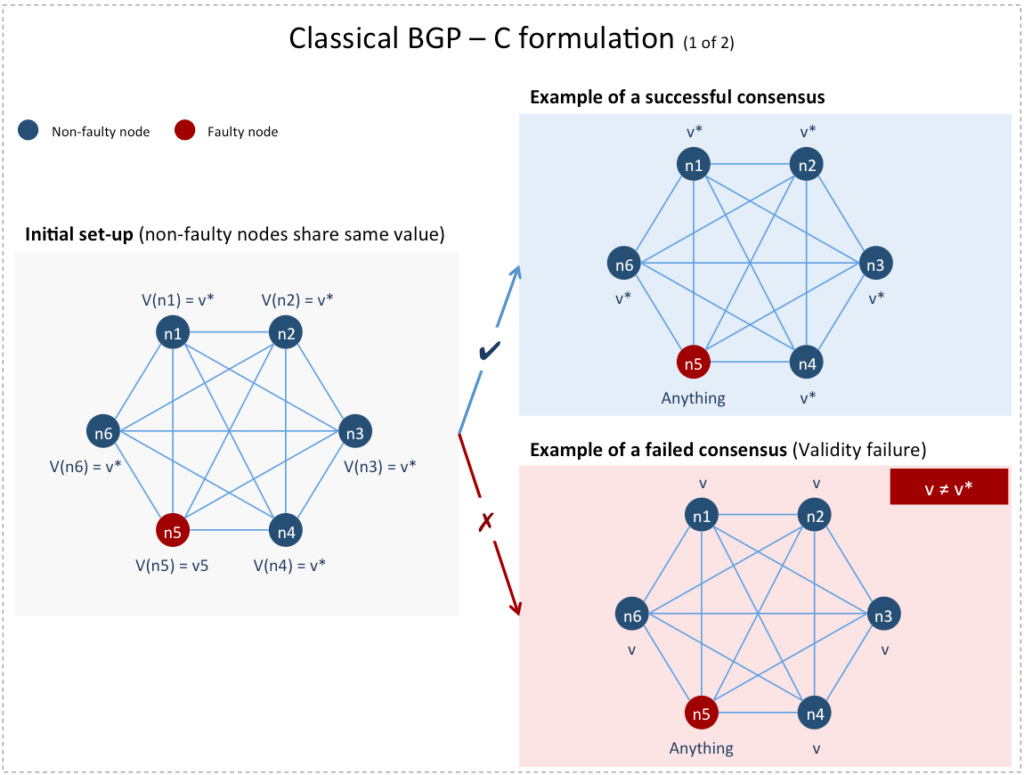
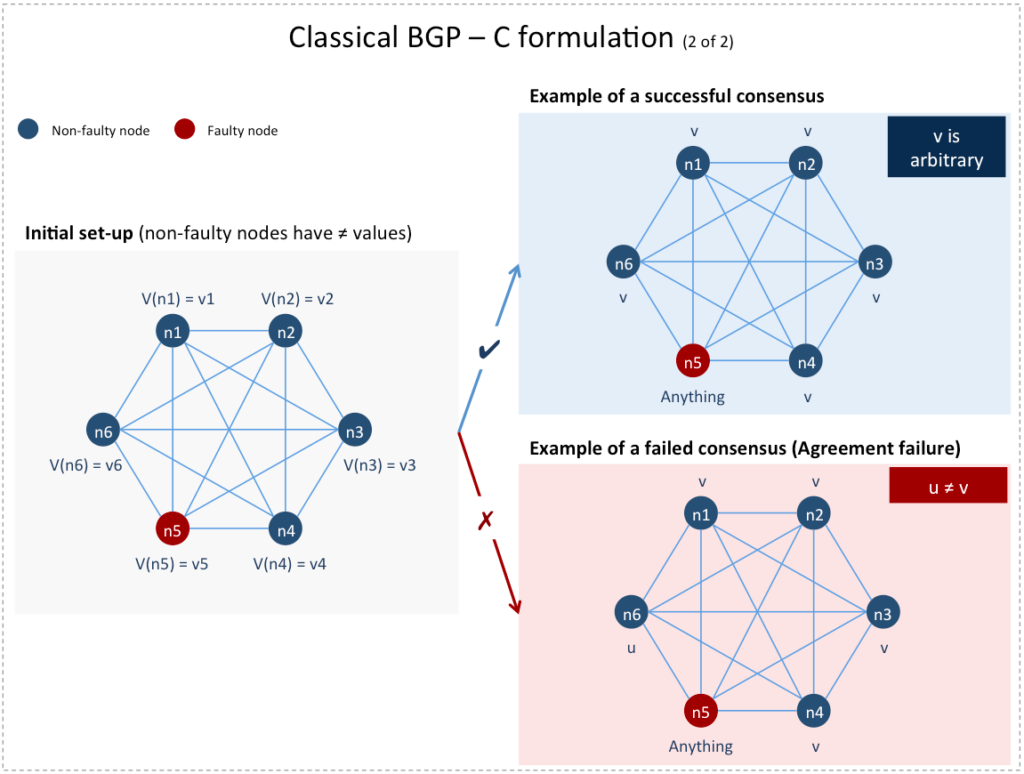
In the (C) formulation [3], each node is endowed with an initial value and the Agreement and Validity criteria become:
- Agreement: All non-faulty nodes agree on the same single value
- Validity: If all non-faulty nodes share the same initial value
 then their agreed upon value must be
then their agreed upon value must be 
BGP consensus formulations equivalence: In what follows we prove the equivalence of all three consensus formulations. More specifically, we show that an algorithm that can solve one of the problems can also be used to solve the other two. We denote by  and
and  any algorithms that respectively solve the (C), (BG), and (IC) formulations of the classical BGP.
any algorithms that respectively solve the (C), (BG), and (IC) formulations of the classical BGP.
1) If there exists an  then there exists an
then there exists an  : Without loss of generality, assume that the initial state of the (BG) formulation consists of general communicating his private value to his lieutenants. Conduct one round of communication and let
: Without loss of generality, assume that the initial state of the (BG) formulation consists of general communicating his private value to his lieutenants. Conduct one round of communication and let  be the value received by lieutenant
be the value received by lieutenant  Set it as node
Set it as node  ‘s initial value. Clearly, we also have that node ‘s initial value is
‘s initial value. Clearly, we also have that node ‘s initial value is  Now run on these initial states:
Now run on these initial states:
- Since the Agreement criteria of
 ensures that all non-faulty nodes agree on the same single value
ensures that all non-faulty nodes agree on the same single value  all honest lieutenants will certainly agree on the same value This guarantees the Agreement criteria of (BG).
all honest lieutenants will certainly agree on the same value This guarantees the Agreement criteria of (BG). - Now suppose that the general is honest (i.e., node is non-faulty). Then all non-faulty lieutenants will share the same initial value
 (i.e., the general’s private value). The Validity criteria of (C) would then ensure that their agreed upon value is This proves that the Agreement criteria of (BG) is satisfied.
(i.e., the general’s private value). The Validity criteria of (C) would then ensure that their agreed upon value is This proves that the Agreement criteria of (BG) is satisfied.
2) If there exists an then there exists an : For each non-faulty node  let denote its private value and associate with it an -dimensional vector
let denote its private value and associate with it an -dimensional vector  whose entries are all initialized to
whose entries are all initialized to  except for the
except for the  entry whose value is set to
entry whose value is set to  In other words, is initially set to
In other words, is initially set to ![[0,\ ..,\ 0,\ v_{j}^{*},\ 0,\ ..,\ 0].](https://delfr.com/wp-content/ql-cache/quicklatex.com-c18896a67ce45a2f9e21b3d3ca8376e5_l3.png "Rendered by QuickLaTeX.com") For each node
For each node  run with node acting as general. Upon termination, update the entry of each with the resulting value computed by node :
run with node acting as general. Upon termination, update the entry of each with the resulting value computed by node :
- If were a non-faulty node, then the (BG) Agreement and Validity criteria will ensure that all non-faulty lieutenants agree on the same value
 As a result, the entry of each will be the same and equal to
As a result, the entry of each will be the same and equal to - If were a faulty node, then the (BG) Agreement criterion will ensure that all non-faulty lieutenants agree on some common value. As a result, the entry of each will be the same.
3) If there exists an then there exists an : For each non-faulty node let denote its private value. Without loss of generality, suppose that the first  nodes are non-faulty (i.e.,
nodes are non-faulty (i.e.,  Run to obtain an interactive consistecy vector
Run to obtain an interactive consistecy vector ![A = [v_{1}^{*},\ ..,\ v_{(n-m)}^{*},\ v_{(n-m+1)},\ ..,\ v_{n}].](https://delfr.com/wp-content/ql-cache/quicklatex.com-c9beb4e5d7e1d418aedcbe68eb7af940_l3.png "Rendered by QuickLaTeX.com") Note that the values
Note that the values  (
( ) are arbitrary as they correspond to faulty nodes. Let each non-faulty node pick the first entry of (i.e.,
) are arbitrary as they correspond to faulty nodes. Let each non-faulty node pick the first entry of (i.e.,  ). This ensures that the Agreement and Validity criteria of (C) are met:
). This ensures that the Agreement and Validity criteria of (C) are met:
- All non-faulty nodes agree on the same single value, namely

- If all non-faulty nodes shared the same initial value then

An impossibility result for the classical BGP: It is not always possible to achieve consensus in a classical BGP setting. In [5] and [6], the authors showed that a necessary and sufficient condition for this to happen is for the total number of nodes to strictly exceed three times the number of faulty ones (i.e.,  ). We will lean on the (IC) formulation to demonstrate that this condition is necessary by showing that it is impossible to reach consensus if
). We will lean on the (IC) formulation to demonstrate that this condition is necessary by showing that it is impossible to reach consensus if  We then rely on the equivalent (BG) formulation to prove that the condition is sufficient by describing an algorithm that achieves consensus whenever the condition is met [5].
We then rely on the equivalent (BG) formulation to prove that the condition is sufficient by describing an algorithm that achieves consensus whenever the condition is met [5].
We first start by formalizing the description of some of the system’s parameters introduced earlier. Recall that the underlying communication network is a digraph G with nodes, at most of which can be faulty. We succinctly denote this set-up by the triplet ( ). It is common to attach a processor
). It is common to attach a processor  to node and let be the set
to node and let be the set  For all practical matters, the terms processor and node can be freely interchanged. Each processor has a private value (or initial state value) drawn from a set
For all practical matters, the terms processor and node can be freely interchanged. Each processor has a private value (or initial state value) drawn from a set  We let
We let  denote the private value of
denote the private value of
The objective is to devise an algorithm that can reach consensus irrespective of which processors are faulty, as long as there are at most of them. A particular instance of () is called a system and is specified by:
- The subset
 of non-faulty processors. Note that
of non-faulty processors. Note that 
- The behavior
 of the processors as defined by the value that processor
of the processors as defined by the value that processor  receives for processor
receives for processor  when the transmission happens over some path in
when the transmission happens over some path in  Clearly, if all processors were non-faulty, would receive the exact value sent by
Clearly, if all processors were non-faulty, would receive the exact value sent by  Faulty processors on the other hand, may behave maliciously and their behavior may vary from one processor to another.
Faulty processors on the other hand, may behave maliciously and their behavior may vary from one processor to another.
We denote the system associated with a given subset  and behavior by
and behavior by  More formally, is defined as the map:
More formally, is defined as the map:

where  is the set of all non-empty strings over (i.e., paths in ) and
is the set of all non-empty strings over (i.e., paths in ) and  is an appropriate set of initial state values. We require that this map satisfies the following:
is an appropriate set of initial state values. We require that this map satisfies the following:
- Initial state specification:
 In other words, maps each processor to its private value.
In other words, maps each processor to its private value. - Behavior: For any path
 let
let  be interpreted as
be interpreted as
“ told
told  that
that  told that .. that
told that .. that  told
told  that its value was “.
that its value was “.
Note that if  then
then  and
and  we expect
we expect  to be equal to
to be equal to  Indeed, by definition, a non-faulty
Indeed, by definition, a non-faulty  must truthfully communicate whatever it receives. A behavior that ensures this condition is said to be consistent with
must truthfully communicate whatever it receives. A behavior that ensures this condition is said to be consistent with 
We rely on this formalism to define the notion of interactive consistency. Let  be the space of all allowable systems on (
be the space of all allowable systems on ( ) i.e., any system with:
) i.e., any system with:
- A set of non-faulty processors satisfying
 and;
and; - A behavior such that is consistent with .
In what follows, it is understood that a system is defined on () and we write  instead of
instead of 
Define the map to be:


where for an allowable system  the output corresponds to the value of processor computed by processor in the (IC) formulation. If
the output corresponds to the value of processor computed by processor in the (IC) formulation. If  the output is taken to be ‘s private value. The consistency vector computed by is then the -dimensional vector:
the output is taken to be ‘s private value. The consistency vector computed by is then the -dimensional vector:
![A = [F_{IC}\ ({\xi_{\mathcal{N}, \sigma}}\ ,\ p_{i},\ p_{1}),\ ..,\ F_{IC}\ ({\xi_{\mathcal{N}, \sigma}}\ ,\ p_{i},\ p_{n}],](https://delfr.com/wp-content/ql-cache/quicklatex.com-ebda66d2efbbc7c90452e94b0e015b19_l3.png "Rendered by QuickLaTeX.com")
Note that  is calculated based on one or more pieces of information available to processor
is calculated based on one or more pieces of information available to processor  Each such piece of information is received by over some path in and is hence of the form
Each such piece of information is received by over some path in and is hence of the form  where
where  We denote the restriction of to paths in starting with by
We denote the restriction of to paths in starting with by 
We say that solves the (IC) formulation if  the following consensus conditions hold:
the following consensus conditions hold:
1) Agreement condition: 

Intuitively, this condition requires that any two non-faulty processors share the same consistency vector. This is the Agreement criterion of the (IC) formulation.
2) Validity condition: 

Intuitively, this condition requires that the entry corresponding to a non-faulty processor in the consistency vector computed by a non-faulty processor be ‘s private value. This is the Validity criterion of the IC formulation.
We can now formally state and prove the classical BGP’s impossibility result:
 and
and  that solves the (IC) formulation of BGP.
that solves the (IC) formulation of BGP.
The proof is a reductio ad absurdum. Suppose that given and  one were able to find such an (i.e., an that achieves consensus on any allowable system
one were able to find such an (i.e., an that achieves consensus on any allowable system  Our objective is to construct three systems whose coexistence would contradict the Agreement criterion needed for to be an acceptable solution.
Our objective is to construct three systems whose coexistence would contradict the Agreement criterion needed for to be an acceptable solution.
Since one can partition into three non-empty subsets  and
and  such that
such that
max( )
) 
Furthermore, since  such that
such that 
Consider the system  where
where  and
and  some behavior consistent with
some behavior consistent with  Then
Then  since
since  Similarly, we can consider the two other systems
Similarly, we can consider the two other systems  and
and  in where
in where  is some behavior consistent with
is some behavior consistent with  and
and  with
with 
Suppose that in addition to being respectively consistent with  and
and  , behaviors
, behaviors  and also satisfied the following constraints:
and also satisfied the following constraints:
- For any
 and are indistinguishable, i.e.,
and are indistinguishable, i.e.,  (this refers to the restriction of a behavior to paths in starting with
(this refers to the restriction of a behavior to paths in starting with 
 behaviors and are indistinguishable, i.e.,
behaviors and are indistinguishable, i.e., 


We could then reach the desired contradiction as follows:
 solely depends on
solely depends on  And since
And since  it is equal to
it is equal to 
 by the Validity criterion of
by the Validity criterion of 
 by design of the behaviors and
by design of the behaviors and 
 by the Validity criterion of
by the Validity criterion of  solely depends on
solely depends on  And since
And since  it is equal to
it is equal to 
- As a result,
 This contradicts the Agreement criterion of (IC) since is consistent with
This contradicts the Agreement criterion of (IC) since is consistent with  and
and 
Consequently, all that is needed to complete the proof is to construct and satisfying these constraints. Note that elements of can be of three types:
1) Strings  that don’t end with a processor in
that don’t end with a processor in  In this case, let
In this case, let

2) Strings of length 1 or 2 that end with a processor in 
 let
let


 and
and 
3) Strings of length greater than 2 that end with a processor in For any string ending with a processor in  and
and 
 let
let
 and
and 
 and
and 

 and
and 
Note that by defining the action of the various behaviors on a string of length  in terms of the action of one of these maps on a string of length
in terms of the action of one of these maps on a string of length  one can easily compute the actual values recursively as they have been previously defined for the cases
one can easily compute the actual values recursively as they have been previously defined for the cases  and
and 
Clearly, behavior is consistent with Indeed,  (i.e., is of the form
(i.e., is of the form  or
or  ), and
), and  and
and  we have
we have  and
and 
Similarly, behavior is consistent with since  (i.e., is of the form
(i.e., is of the form  or ), and and
or ), and and  we have
we have  and
and 
Finally, behavior is consistent with since  (i.e., is of the form or ), and and we have
(i.e., is of the form or ), and and we have  and
and 
Next we show that  behaviors and are indistinguishable (i.e.,
behaviors and are indistinguishable (i.e.,  ) and behaviors and are indistinguishable (i.e.,
) and behaviors and are indistinguishable (i.e.,  ).
).
First, note that not ending in a processor in the construction mandates that  In particular this holds true for such strings that start with a processor in
In particular this holds true for such strings that start with a processor in  and so
and so  In addition, this holds true for such strings that start with a processor in
In addition, this holds true for such strings that start with a processor in  and so
and so 
To show it for strings ending in a processor in we proceed by induction on the length of  If is of length 1, i.e.,
If is of length 1, i.e.,  the construction mandates that
the construction mandates that  and so
and so  and
and  are indistinguishable over elements of Similarly, the construction mandates that
are indistinguishable over elements of Similarly, the construction mandates that  and so
and so  and
and  are indistinguishable over elements of
are indistinguishable over elements of
Now suppose that the result holds true for strings of length  that end in a processor in Relevant strings of length
that end in a processor in Relevant strings of length  must be of the form
must be of the form  or
or  (
( ). We must show that:
). We must show that:
 and
and 
 and
and 
We will show it only for 1. as 2. can be done in exactly the same way:
 (by construction), which is equal to
(by construction), which is equal to  (by induction), which in turn is equal to
(by induction), which in turn is equal to  (by construction).
(by construction). (by construction), which is equal to
(by construction), which is equal to  (by induction), which in turn is equal to
(by induction), which in turn is equal to  (by construction).
(by construction). (by construction), which is equal to
(by construction), which is equal to  (by construction).
(by construction).
Here is a summary of the three systems for the case  and
and 
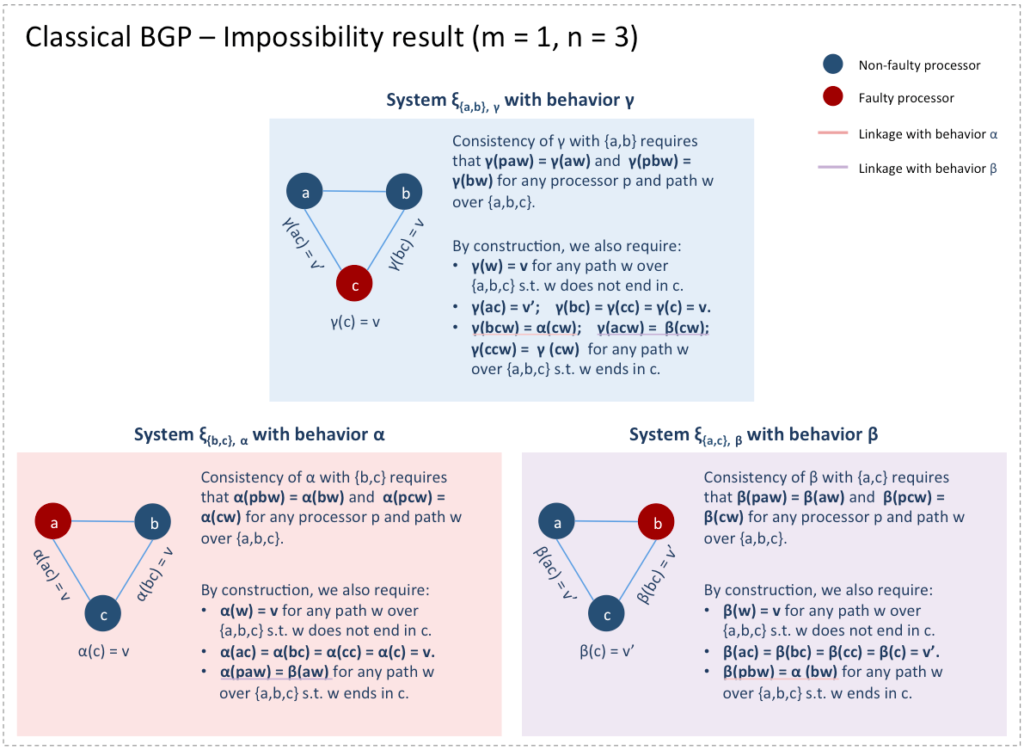
The intuition is as follows:
- From the point of view of processor
 systems
systems  and
and  are indistinguishable because and are identical when restricted to strings starting with
are indistinguishable because and are identical when restricted to strings starting with  As a result, cannot tell whether is faulty (i.e., system is applicable) or is (i.e., system is applicable). In order not to violate the Validity condition in
As a result, cannot tell whether is faulty (i.e., system is applicable) or is (i.e., system is applicable). In order not to violate the Validity condition in  is then forced to register for the value
is then forced to register for the value 
- Similarly, from the point of view of processor
 systems and
systems and  are indistinguishable because and are identical when restricted to strings starting with
are indistinguishable because and are identical when restricted to strings starting with  As a result, cannot tell whether is faulty (i.e., system is applicable) or is (i.e., system is applicable). In order not to violate the Validity condition in
As a result, cannot tell whether is faulty (i.e., system is applicable) or is (i.e., system is applicable). In order not to violate the Validity condition in  is then forced to register for the value
is then forced to register for the value 
- But in order not to violate the Agreement condition in system
 processors and must both register the same value for processor
processors and must both register the same value for processor  However, this is not the case since registered
However, this is not the case since registered  while registered
while registered
Note that this proof fails if  This is because any 3-subset partition
This is because any 3-subset partition  of would have at least one subset with
of would have at least one subset with  This would cause system
This would cause system  to be not allowable (i.e.,
to be not allowable (i.e.,  ).
).
Solving the classical BGP for : We now show that the necessary condition is also sufficient. We do so by describing an algorithm that achieves consensus in the (BG) formulation.
For a given allowable system in  and processor
and processor  acting as general, we make explicit the dependence of on
acting as general, we make explicit the dependence of on  and and write
and and write  We define the map
We define the map  to be:
to be:


where the output corresponds to the value that processor computes for  We say that solves the (BG) formulation if
We say that solves the (BG) formulation if  the following consensus conditions hold:
the following consensus conditions hold:
1. Agreement: 

Intuitively, non-faulty lieutenants must compute the same value for general .
2. Validity: If  then
then 

Intuitively, this requires that the value that a non-faulty lieutenant computes for a non-faulty general be ‘s private value.
To devise such a map, we introduce a recursive algorithm  over that takes three inputs: a subset
over that takes three inputs: a subset  a processor
a processor  and an iteration variable
and an iteration variable  such that
such that 
- Base case
 When is 0, processor
When is 0, processor  sends its value to every other processor
sends its value to every other processor  who receives value
who receives value  and attributes it to
and attributes it to 
- General case for

i) Processor sends its value to every other 
ii) Processor  receives value
receives value  A new instance of algorithm is then executed for each with an iteration counter set to
A new instance of algorithm is then executed for each with an iteration counter set to  and a processor set
and a processor set  Each such iteration sends
Each such iteration sends  to the remaining processors
to the remaining processors  This step runs an instance of
This step runs an instance of  for each
for each  totaling
totaling  instances.
instances.
iii)  let
let  denote the value that computed for
denote the value that computed for  under algorithm
under algorithm  in step ii). Subsequently, computes the following value and assigns it to
in step ii). Subsequently, computes the following value and assigns it to 

We can represent the above logic in pseudo-code as follows:
Define 

If is equal to 
For each  do the following:
do the following:
receives
assigns the value  to
to

Else, if  :
:
For each do the following:
receives  and sets it as its private value
and sets it as its private value
Run  and store the resulting
and store the resulting  vector
vector ![[v_{1i},\ ..,\ v_{ji},\ ..,\ v_{si}],](https://delfr.com/wp-content/ql-cache/quicklatex.com-751e863da2f9b69630b53bac9c2b446a_l3.png "Rendered by QuickLaTeX.com") where
where  denotes the value that computed for
denotes the value that computed for  and where
and where 
For each  does the following:
does the following:
Assign  to where the index
to where the index 
Return the vector ![[w_{1k},\ ..,\ w_{jk},\ ..,\ w_{sk}],](https://delfr.com/wp-content/ql-cache/quicklatex.com-20aacad8dd368b37c4fb038ef76e5d42_l3.png "Rendered by QuickLaTeX.com") where
where 
Algorithm invokes algorithms of order  namely,
namely, 

 . Similarly, each algorithm of order invokes others of order
. Similarly, each algorithm of order invokes others of order  The lowest order ones have
The lowest order ones have  and are called
and are called  times. Finally, each algorithm of order 0 sends
times. Finally, each algorithm of order 0 sends  messages, resulting in a total of
messages, resulting in a total of  messages and a complexity of
messages and a complexity of 
 we now define the map
we now define the map  as follows:
as follows:

where  is the appropriate component of the
is the appropriate component of the  vector returned by
vector returned by  with an iteration count set to (the maximal number of faulty processors allowed).
with an iteration count set to (the maximal number of faulty processors allowed).
We claim that this map solves the (BG) formulation of the classical BGP whenever  Before we prove its correctness, we look at two clarifying examples (we will drop the superscript for ease of notation)
Before we prove its correctness, we look at two clarifying examples (we will drop the superscript for ease of notation)
Example 1,  Let
Let  and
and  be faulty. There are two cases depending on whether the general is faulty or not. We will refer to processors by their indices and enclose received values in brackets and computed values in parentheses:
be faulty. There are two cases depending on whether the general is faulty or not. We will refer to processors by their indices and enclose received values in brackets and computed values in parentheses:
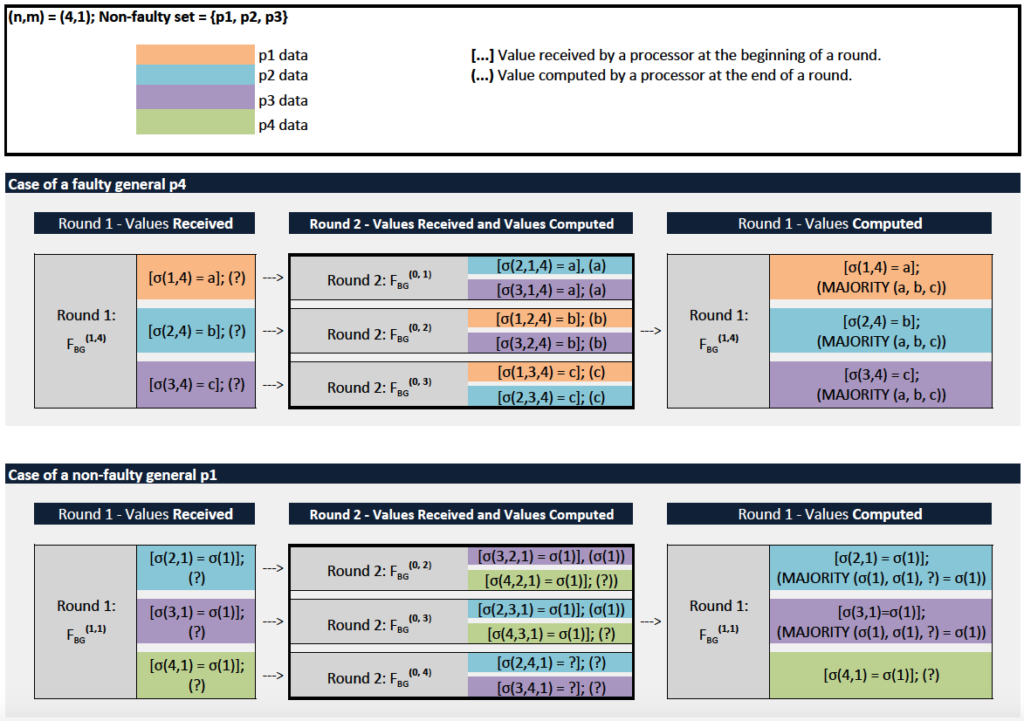
We describe the case of a faulty general (the other one can be analyzed similarly):
- Algorithm
 is invoked and sends its value to every lieutenant
is invoked and sends its value to every lieutenant 
- Lieutenant receives value
 Let
Let  and
and  Subsequently, each
Subsequently, each  acts as general and runs a new instance of algorithm
acts as general and runs a new instance of algorithm  to send
to send  to the remaining two lieutenants. More specifically:
to the remaining two lieutenants. More specifically:
-
- Under

 sends
sends  to lieutenant
to lieutenant  and
and  to lieutenant
to lieutenant 
- Under

 sends
sends  to lieutenant
to lieutenant  and
and  to lieutenant
to lieutenant - Finally, under

 sends
sends  to lieutenants and
to lieutenants and  to lieutenant
to lieutenant 
- Under
- Since the algorithm is running instances with
 it must be that lieutenants and
it must be that lieutenants and  compute a value equals to under
compute a value equals to under  Similarly, lieutenants and compute under
Similarly, lieutenants and compute under  while lieutenants and compute under
while lieutenants and compute under 
- Finally, the value that lieutenants
 and computes for under
and computes for under  is equal to:
is equal to:

Example 2,  Let
Let  and
and  be faulty. Here too, there are two cases depending on whether the general is faulty or not. We treat the case of a faulty general
be faulty. Here too, there are two cases depending on whether the general is faulty or not. We treat the case of a faulty general  (the other case can be analyzed similarly) and follow the convention of enclosing received values in brackets and computed values in parentheses:
(the other case can be analyzed similarly) and follow the convention of enclosing received values in brackets and computed values in parentheses:
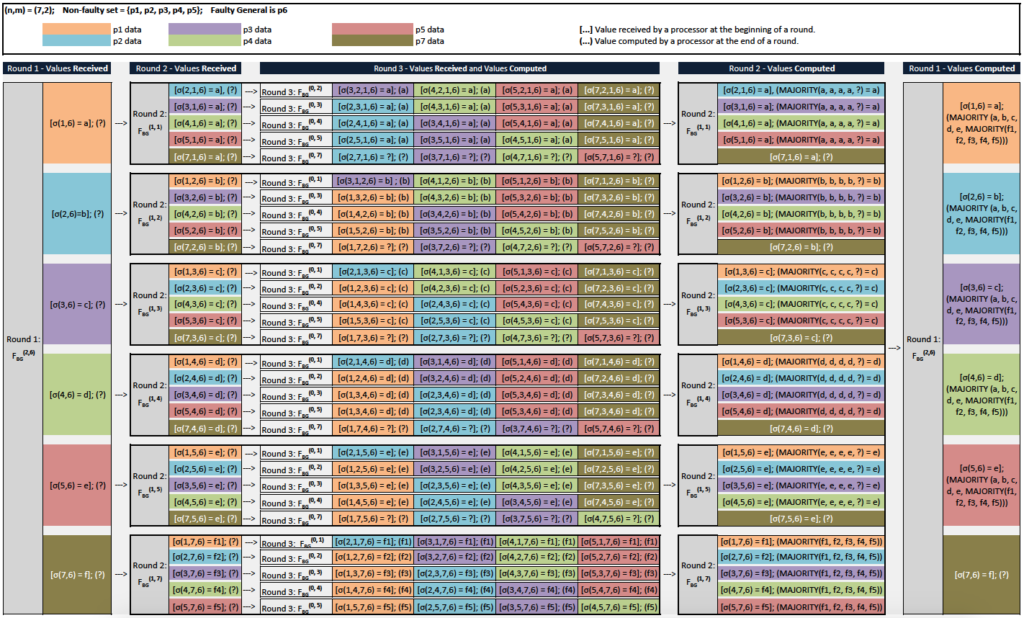
- Algorithm
 is invoked and processor
is invoked and processor  sends its value to every lieutenant
sends its value to every lieutenant 
- Lieutenant receives value
 Let
Let 



 and
and  Subsequently, each
Subsequently, each  acts as general and runs
acts as general and runs  to send
to send  to the other five lieutenants.
to the other five lieutenants. - The next step is to compute the action of
 We illustrate it for
We illustrate it for  where processor acts as general and sends its value
where processor acts as general and sends its value  to the remaining five lieutenants
to the remaining five lieutenants  . In this case, lieutenant receives
. In this case, lieutenant receives  Subsequently, each
Subsequently, each  acts as general and runs a new instance of algorithm
acts as general and runs a new instance of algorithm  to send
to send  to the remaining four lieutenants:
to the remaining four lieutenants:
-
- Under processor acts as general and sends its value
 to lieutenants
to lieutenants  Lieutenant
Lieutenant  receives
receives 
- Under processor acts as general and sends its value
 to lieutenants
to lieutenants  Lieutenant receives
Lieutenant receives 
- Under
 processor
processor  acts as general and sends its value
acts as general and sends its value  to lieutenants
to lieutenants  Lieutenant receives
Lieutenant receives 
- Under
 processor
processor  acts as general and sends its value
acts as general and sends its value  to lieutenants
to lieutenants  Lieutenant receives
Lieutenant receives 
- Under
 faulty processor
faulty processor  acts as general and sends some unknown value(s) to lieutenants
acts as general and sends some unknown value(s) to lieutenants  Each lieutenant
Each lieutenant  receives an unknown value
receives an unknown value  that we denote by a question mark (?).
that we denote by a question mark (?).
- Under
- Since each received values also serves as the computed value that the relevant processor attributes to
 We can now compute the value that the non-faulty lieutenants
We can now compute the value that the non-faulty lieutenants  and compute for under
and compute for under 
-
- Lieutenant computes:
- Lieutenant


-
- Lieutenant computes:
- Lieutenant


-
- Lieutenant computes:
- Lieutenant


-
- Lieutenant computes:
- Lieutenant


- Similarly, one can evaluate

-
- For
 we find that the values that the non-faulty lieutenants
we find that the values that the non-faulty lieutenants  and compute for are all equal to
and compute for are all equal to 
- For
 we find that the values that the non-faulty lieutenants
we find that the values that the non-faulty lieutenants  and compute for are all equal to
and compute for are all equal to 
- For
 we find that the values that the non-faulty lieutenants
we find that the values that the non-faulty lieutenants  and compute for are all equal to
and compute for are all equal to 
- For
 we find that the values that the non-faulty lieutenants and compute for are all equal to
we find that the values that the non-faulty lieutenants and compute for are all equal to 
- For
 we find that the values that the non-faulty lieutenants
we find that the values that the non-faulty lieutenants  and compute for are all equal to
and compute for are all equal to  where
where  denotes the value
denotes the value  that communicates to processor
that communicates to processor  under
under  These values may be different from each other since is faulty.
These values may be different from each other since is faulty.
- For
- Finally, the value that the non-faulty lieutenants
 compute for under are as follows:
compute for under are as follows:
- Lieutenant computes

- Lieutenant computes
- Lieutenant computes
- Lieutenant computes:
- Lieutenant
Proof of the algorithm’s correctness: We wrap up this section with a correctness proof for the aforementioned algorithm whenever .
Let  be a set of processors, with acting as general for some
be a set of processors, with acting as general for some  . Furthermore, assume that at most out of processors can be faulty, with
. Furthermore, assume that at most out of processors can be faulty, with  We claim that the vector returned by satisfies the Agreement and Validity conditions of the (BG) consensus formulation.
We claim that the vector returned by satisfies the Agreement and Validity conditions of the (BG) consensus formulation.
We will prove this by induction on and Note that serves as the iteration count in as well as the maximal number of faulty processors in .
Base case: Given any subset  such that
such that  and such that all processors in
and such that all processors in  are non-faulty (this is possible since there are at most faulty processors), algorithm
are non-faulty (this is possible since there are at most faulty processors), algorithm  satisfies the Validity and Agreement conditions
satisfies the Validity and Agreement conditions  This should be rather clear since when is executed, each
This should be rather clear since when is executed, each  receives and registers the value
receives and registers the value  As a result, all lieutenants agree on ‘s private value, causing the Validity and Agreement conditions to be upheld.
As a result, all lieutenants agree on ‘s private value, causing the Validity and Agreement conditions to be upheld.
Induction step: Suppose that  and that
and that 
 satisfies the Agreement and Validity conditions whenever
satisfies the Agreement and Validity conditions whenever  Now assume that
Now assume that  Our objective is to prove that also satisfies both conditions. Without loss of generality, we assume that the first processors
Our objective is to prove that also satisfies both conditions. Without loss of generality, we assume that the first processors  are non-faulty and consider the two cases corresponding to a faulty or non-faulty general
are non-faulty and consider the two cases corresponding to a faulty or non-faulty general
The case of a faulty general : When is executed, general sends a value  to each lieutenant These values may be arbitrary and different than ‘s private value given the general’s faulty nature.
to each lieutenant These values may be arbitrary and different than ‘s private value given the general’s faulty nature.
The next step is for the algorithm to execute for each lieutenant First note that since  we have
we have  . We can then use the induction hypothesis and assume that
. We can then use the induction hypothesis and assume that  satisfies the Agreement and Validity conditions.
satisfies the Agreement and Validity conditions.
- If is non-faulty (i.e.,
 ), its resulting
), its resulting  vector will be of the form
vector will be of the form ![[\sigma(p_{i}\ p_{k}),\ ..,\ \sigma(p_{i}\ p_{k}),\ ...]](https://delfr.com/wp-content/ql-cache/quicklatex.com-977af89d402aa87b2d84ff9c310bf107_l3.png "Rendered by QuickLaTeX.com") where the first
where the first  entries are all equal to
entries are all equal to  by virtue of ‘s Validity condition.
by virtue of ‘s Validity condition. - If is faulty, its resulting vector must have the first entries all equal. Indeed, these are the values computed by the non-faulty lieutenants on behalf of the faulty processor and must all be equal by virtue of ‘s Agreement condition.
The subsequent majority function applied at the level of each non-faulty processor will then have the same set of inputs and as a result, compute the same output. This guarantees that satisfies the Agreement condition. The Validity condition is futile in this case since the general is known to be faulty.
The case of a non-faulty general : When is executed, general sends a value  to each lieutenant They are all equal to ‘s private value.
to each lieutenant They are all equal to ‘s private value.
is subsequently executed for each lieutenant Since we have . As a result, we can invoke the induction hypothesis and assume that satisfies the Agreement and Validity conditions.
- If is non-faulty (i.e., ), its resulting vector will be of the form
![[\sigma(p_{k}),\ ..,\ \sigma(p_{k}),\ ...]](https://delfr.com/wp-content/ql-cache/quicklatex.com-3788462f85ffd1aefc39fcc51efac53c_l3.png "Rendered by QuickLaTeX.com") where the first
where the first  entries are all equal to
entries are all equal to  by virtue of ‘s Validity condition.
by virtue of ‘s Validity condition. - If is faulty, its resulting vector must have the first entries all equal. Indeed, these are the values computed by the non-faulty lieutenants on behalf of the faulty processor and must all be equal by virtue of ‘s Agreement condition.
Since and  it must be that
it must be that  The majority of the
The majority of the  lieutenants are thus non-faulty. The last step in the execution of will then guarantee that all non-faulty lieutenants compute the same value
lieutenants are thus non-faulty. The last step in the execution of will then guarantee that all non-faulty lieutenants compute the same value  for
for  ensuring as such that the Validity and Agreement conditions are observed.
ensuring as such that the Validity and Agreement conditions are observed.
4. FLP impossibility result
We now consider a different class of consensus problems for which no algorithm can always reach consensus in finite time. This was first stated and proved in [4] and came to be known as the FLP impossibility result. We start by defining the relevant consensus problem before we state and prove this seminal result.
System model: For this class of consensus problems, we consider systems with arbitrary network topologies consisting of a pre-defined set of static nodes or processors  for some integer
for some integer  The underlying communication channel is assumed to be reliable and any faulty behavior is modeled at the level of the processor as we describe later under the node failure regime. No constraints are imposed on the nature of the messages which could be oral or signed. Most importantly, the class of systems considered are fully asynchronous.
The underlying communication channel is assumed to be reliable and any faulty behavior is modeled at the level of the processor as we describe later under the node failure regime. No constraints are imposed on the nature of the messages which could be oral or signed. Most importantly, the class of systems considered are fully asynchronous.
In what follows, we introduce numerous definitions to help formalize the system model:
- Processors communicate by sending each-other messages. A message is defined to be a pair
 where
where  is the destination processor and a message value destined to taken from a fixed message set
is the destination processor and a message value destined to taken from a fixed message set 
- A message system
 is a buffer of messages that have been sent but not yet received by their destined processor. Adding a message to is achieved by executing a send function:
is a buffer of messages that have been sent but not yet received by their destined processor. Adding a message to is achieved by executing a send function:

 which places
which places  in
in
- Removing a message from requires the execution of a receive function:

 which does one of two things:
which does one of two things:
-
- Returns
 i.e., leaves unchanged, or
i.e., leaves unchanged, or - Returns a message value taken from the subset of all messages in intended to and deletes from
 We say that message has been delivered.
We say that message has been delivered.
- Returns
- The
 function is subject to the condition that if
function is subject to the condition that if  is performed infinitely may times, every message
is performed infinitely may times, every message  intended to gets eventually delivered.
intended to gets eventually delivered. - The notion of asynchronicity is embedded within the definition of the receive function. Indeed, the function acts in a non-deterministic way by having the right to return a finite number of times in response to even though an intended message exists in Note that if this right were granted an infinite number of times, the aforementioned condition would fail to hold.
- Each processor
 is characterized by a set of attributes consisiting of:
is characterized by a set of attributes consisiting of:
- An input register
 whose value is a single bit.
whose value is a single bit. - An internal storage unit of infinite capacity that we denote
 .
. - A program counter that we refer to as
 .
. - An output register
 that can take values from
that can take values from  where denotes a value other than or .
where denotes a value other than or .
- An input register
- At any point
 in time, we can concisely represent the state of processor by the four-tuple
in time, we can concisely represent the state of processor by the four-tuple  We refer to it as the internal state of at time
We refer to it as the internal state of at time  At
At  each processor starts at an initial state characterized by an empty input register and output register set to
each processor starts at an initial state characterized by an empty input register and output register set to 
inititial state internal state
internal state
- By exchanging messages, processors change their internal states. A primitive step by processor consists of two phases:
- Call method and obtain a value

- Depending on ‘s internal state and on
 enters a new internal state and sends a finite number of messages to other processors (i.e., places them in by executing the
enters a new internal state and sends a finite number of messages to other processors (i.e., places them in by executing the  function).
function).
- Call method
- The change of ‘s internal state is dictated by a deterministic transition function
 The only constraint on
The only constraint on  is that it cannot change the value of ‘s output register once reaches a decision (i.e., when
is that it cannot change the value of ‘s output register once reaches a decision (i.e., when  ). In other words, the output register is write once. More formally, we can let
). In other words, the output register is write once. More formally, we can let  denote the state space of
denote the state space of  i.e., the space of all four-tuples
i.e., the space of all four-tuples  We let
We let  denote a discrete unit of time corresponding to when primitive step #
denote a discrete unit of time corresponding to when primitive step # was applied. The transition function can be generically defined as:
was applied. The transition function can be generically defined as:

![[(x_{p}(t),\ s_{p}(t),\ c_{p}(t),\ y_{p}(t)),\ m]\ \rightarrow](https://delfr.com/wp-content/ql-cache/quicklatex.com-14976157fe678ee6755510381906276c_l3.png "Rendered by QuickLaTeX.com")

such that 
- At any given time
 the system will be in a certain configuration
the system will be in a certain configuration  which corresponds to the internal states of all processors in along with the content of the message buffer at time
which corresponds to the internal states of all processors in along with the content of the message buffer at time 
![[(x_{1}(t),\ s_{1}(t),\ c_{1}(t),\ y_{1}(t)),\ ..,\ (x_{n}(t),\ s_{n}(t),\ c_{n}(t),\ y_{n}(t)),\ \mathcal{M}(t)]](https://delfr.com/wp-content/ql-cache/quicklatex.com-ea4296e13ff789143c35f3746f87dddd_l3.png "Rendered by QuickLaTeX.com")
- At the initial configuration of the system corresponds to the initial states
 and initial input register values
and initial input register values  of each processor
of each processor  as well as an empty message buffer
as well as an empty message buffer 

![[(x_{1}(0),\ s_{0}(t),\ c_{0}(t),\ b),\ ..,\ (x_{n}(0),\ s_{n}(0),\ c_{n}(0),\ b),\ \emptyset]](https://delfr.com/wp-content/ql-cache/quicklatex.com-4c623772355ad355e6e4af40297d805a_l3.png "Rendered by QuickLaTeX.com")
- Moving from configuration to
 occurs after the execution of primitive step # which is fully determined by a pair
occurs after the execution of primitive step # which is fully determined by a pair  We refer to the receipt of by following primitive step # as the event
We refer to the receipt of by following primitive step # as the event  Recall that could be as per the definition of the function. We say that one moves from to by applying event
Recall that could be as per the definition of the function. We say that one moves from to by applying event  and write:
and write:

- The event
 can always be applied to any configuration and so it is always possible for a processor to take another step.
can always be applied to any configuration and so it is always possible for a processor to take another step. - We say that a configuration has decision value
 if some processor is in a decision state with
if some processor is in a decision state with  This definition does not impose any restriction on the number of decision values that a configuration may have. Indeed, it is conceivable for different processors in a configuration to have reached different decision values. We will however impose a restriction when we later define the Agreement criterion of the consensus problem.
This definition does not impose any restriction on the number of decision values that a configuration may have. Indeed, it is conceivable for different processors in a configuration to have reached different decision values. We will however impose a restriction when we later define the Agreement criterion of the consensus problem. - A schedule starting at configuration is a finite or infinite sequence of events that can be sequentially applied to
 The associated sequence of steps that generates these specific events is called a run. A finite schedule
The associated sequence of steps that generates these specific events is called a run. A finite schedule  of length
of length  starting at results in another configuration
starting at results in another configuration  such that:
such that:

In this finite-length case, we say that  is reachable from A configuration that is reachable from some initial configuration is said to be accessible.
is reachable from A configuration that is reachable from some initial configuration is said to be accessible.
Failure regime: The nodes are assumed to operate under a crash failure regime where a given processor can either be operational or dead. More specifically, we say that a processor is non-faulty in a given run if it can take infinitely many steps. This is a weaker version than the byzantine regime we considered in section 3. The justification for this choice lies in the fact that impossibility results that hold in a relatively basic failure regime would also hold in a stronger one including the byzantine model.
Consensus problem: We are now in a position to specify what is meant for an algorithm to reach consensus for this class of system models. To do so, we describe the Agreement, Validity and Termination criteria that an algorithm must observe if it were to solve the consensus problem:
1. Agreement: No accessible configuration can have more than one decision value.
2. Validity:  some accessible configuration has decision value In other words, this criterion ensures that there are no trivial solutions to the consensus problem.
some accessible configuration has decision value In other words, this criterion ensures that there are no trivial solutions to the consensus problem.
3. Termination: Before stating the Termination criterion, we define what is meant by an admissible and deciding run:
- A run is admissible if at most one processor is faulty and if all messages destined to non-faulty processors are eventually received.
- A run is deciding if some processor reaches a decision state in that run.
The Termination criterion requires every admissible run to be a deciding run. Note that this criterion only requires that some processor makes a decision rather than all processors deciding. Here too, an impossibility result that holds in this weaker context will certainly hold in the stronger setting that requires all processors to decide. An important observation is that the Termination criterion must hold deterministically i.e., every time the consensus algorithm is executed.
In [4], the authors refer to a consensus prototcol or algorithm that satisfies the Agreement and Validity conditions as partially correct. If it also satsfies the Termination criterion, then it is said to be totally correct in spite of one fault. The FLP impossibility result can then be stated as follows:
No consensus protocol is totally correct in spite of one fault
In order to prove this, the authors demonstrate that every partially correct protocol has some admissible run that is not a deciding run. In other words, if the Agreement and Validity conditions were respected then the Termination criterion would fail. We now turn to the reductio ad absurdum proof articulated in [4].
Proof of the FLP impossibility result: The gist of the proof consists in showing that if all three criteria are uphelp, then one could still find an admissible run that avoids taking any decision at all times, violating as such the Termination criterion. To do so, we proceed in two steps:
- We first show that there exists at least one initial configuration that admits at least two schedules leading to two different decision values. Such a characteristic is referred to as bivalency.
- We then show that given any bivalent configuration, there exists a schedule that leads to another bivalent configuration.
Intuitively, a bivalent configuration is one whose decision is not known a priori. Creating an inifnite chain of such configurations will clearly violate the Termination criterion.
Lemma A: In a totally correct consensus protocol in spite of one fault, there exists a bivalent initial configuration.
Let be a configuration at some time and let  be the set of decision values of all configurations reachable from Clearly. must be a subset of
be the set of decision values of all configurations reachable from Clearly. must be a subset of  i.e.,
i.e., 
- If
 we say that is bivalent.
we say that is bivalent. - If
 (
( ) we say that is -valent (-valent).
) we say that is -valent (-valent).
We first claim that  To see why, note the following:
To see why, note the following:
- There always exists an admissible run starting at This is because by assumption, we consider systems where at most one processor is faulty and such that for all non-faulty processors , the condition we imposed on the function ensures that all messages destined to get eventually delivered.
- Since the system is assumed to be totally correct, every admissible run must also be a deciding run. As a result, the set of decision values of all configurations reachable from cannot be the empty set.
We now now proceed with a reductio ad absurdum proof of Lemma A.
- Suppose that Lemma A does not hold, i.e., in a totally correct consensus prototcol in spite of one fault, there does not exist any bivalent initial configuration.
- We already established that for any configuration

 In particular,
In particular,  If furthermore no bivalent initial configuartion exists, then any initial configuration
If furthermore no bivalent initial configuartion exists, then any initial configuration  must either be 0-valent or 1-valent.
must either be 0-valent or 1-valent. - This result, coupled with the Validity criterion shows that there exists distinct initial configurations and
 such that is 0-valent and 1-valent (i.e.,
such that is 0-valent and 1-valent (i.e.,  and
and 
- Next, note that any two initial configurations differ only in the initial value of a subset of their processors. In other words:


where  such that
such that 
- Now observe that one can transform any initial into another initial through a sequence of adjacent configurations where each configuration in the sequence differs from its neighbor(s) in the initial value of a single processor. For example, starting at
 one can apply the following steps to get to :
one can apply the following steps to get to :
Step : Replace  with
with  (leave everything else intact):
(leave everything else intact):


Step : Replace  with
with  (leave everything else intact):
(leave everything else intact):


Step : Replace  with
with  and get
and get 


- Since any initial configuration must either be -valent or -valent, and since and have different valencies, it must be that in the sequence of adjacent configurations leading from to there exists a -valent initial configuration
 adjacent to a -valent initial configuration
adjacent to a -valent initial configuration  (
( where the two differ only in the initial value of
where the two differ only in the initial value of 
- Consider an admissible run starting at initial configuration and such that processor is the only faulty processor and such that it is assumed to have crashed prior to starting the run. By the total correctness assumption, this admissible run must also be a deciding one. Let be its corresponding schedule.
- Since and differ only in ‘s initial value, and since this value is irrelevant to in the context of this run ( is assumed to be a dead processor that takes no steps in the run), one can apply the same schedule on the initial configuration
 Furthermore, the deterministic transition functions will ensure that the two runs on and result in the same decision.
Furthermore, the deterministic transition functions will ensure that the two runs on and result in the same decision. - If the decision is
 then this would contradict ‘s -valency. Otherwise ‘s -valency would be contradicted. Q.E.D.
then this would contradict ‘s -valency. Otherwise ‘s -valency would be contradicted. Q.E.D.
Next, we show that given a totally correct consensus protocol in spite of one fault, we can always derive a bivalent configuration from another bivalent one by applying an adequate sequence of events.
Lemma B: Let be a bivalent configuration at time Let  be an event applicable to Let be the set of all configurations reachable from without applying
be an event applicable to Let be the set of all configurations reachable from without applying  and
and  the set
the set  and
and  is applicable to
is applicable to  . In a totally correct consensus protocol in spite of one fault, we claim that must contain at least one bivalent configuration.
. In a totally correct consensus protocol in spite of one fault, we claim that must contain at least one bivalent configuration.
To prove it, we lean on a number of sub-lemmas. In the proofs below we drop the explicit dependence of a configuration on a particular time instance since knowledge of the exact time or step when a configuration materializes is not necessary for our purposes:
Sub-lemma B.1: The event is applicable to every configuration 
- The event is clearly applicable to configuration (by the assumption in Lemma B).
- Furthermore, messages could be delayed arbitrarily (due to the asynchronous nature of the system model).
- As a result, one could arbitrarily delay the receipt of message value by processor
 Q.E.D.
Q.E.D.
Sub-lemma B.2: If the set does not contain any bivalent configuration, then it must contain both a -valent and a -valent configuration.
- Since is a bivalent configuration (by the assumption in Lemma B), there exists a 0-valent and 1-valent configurations
 and
and  reachable from We now show how to derive a 0-valent configuration from that is an element of
reachable from We now show how to derive a 0-valent configuration from that is an element of  We can replicate the same logic to derive a 1-valent configuration from
We can replicate the same logic to derive a 1-valent configuration from 
- Two cases arise depending on whether is an element of or not.
- If
 let
let  be the configuration
be the configuration  This is possible bySub-lemma B.1. Clearly,
This is possible bySub-lemma B.1. Clearly,  by the definition of the set
by the definition of the set - If
 then the event was applied sometime before reaching configuration
then the event was applied sometime before reaching configuration  Let be the configuration immediately obtained after applying
Let be the configuration immediately obtained after applying  In this case, is reachable from .
In this case, is reachable from .
- If
- If has no bivalent configuration, then must be univalent (we’ve shown as part of Lemma A that it cannot be ):
- In the first case above, is reachable from . Since is 0-valent, then so must be

- In the second case, is reachable from If were 1-valent, then would also have to be 1-valent. Since is 0-valent, then is 0-valent. Q.E.D.
- In the first case above,
Sub-lemma B.3: Two configurations are said to be neighbors if one can be reached from the other through the application of a single event. If has no bivalent configurations, then there must exist two neighboring configurations  and
and  such that configuration
such that configuration  is 0-valent and configuration
is 0-valent and configuration  is 1-valent.
is 1-valent.
- By Sub-lemma B.2 we know that must contain both a 0-valent configuration and a 1-valent configuration
 Let and be the two configurations in such that
Let and be the two configurations in such that  and
and 
- Since all the elements of are reachable from it must be that and are reachable from Let
 be the last common configuration in the two distinct paths from to and as depicted below:
be the last common configuration in the two distinct paths from to and as depicted below:
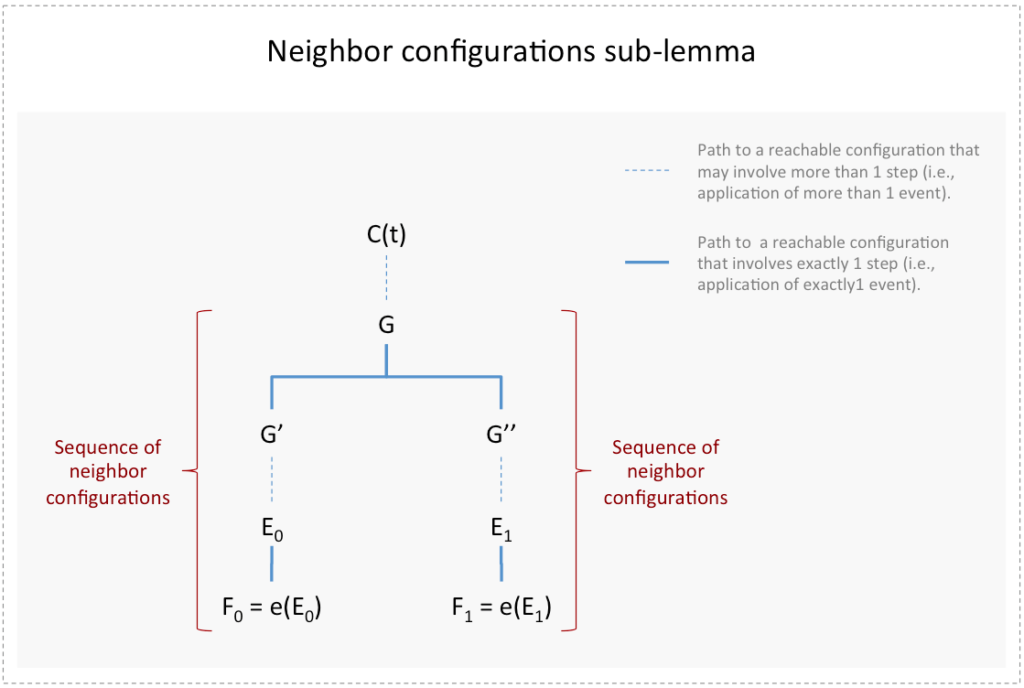
- Suppose that for any two neighboring configurations
 and
and  and
and  cannot have different valences. We’ve seen as part of Lemma A that
cannot have different valences. We’ve seen as part of Lemma A that  and cannot have an empty set of decision values either. Furthermore, being elements of
and cannot have an empty set of decision values either. Furthermore, being elements of  they cannot be bivalent by the condition in Sub-lemma B.3. As a result, and must have the same valence.
they cannot be bivalent by the condition in Sub-lemma B.3. As a result, and must have the same valence. - In particular, since configurations and are linked by a sequence of neighbors, it must be that
 and
and  share the same valence. Given that
share the same valence. Given that  is 0-valent, it must be that is 0-valent. By a similar argument, and using the sequence of neighbors linking and
is 0-valent, it must be that is 0-valent. By a similar argument, and using the sequence of neighbors linking and  we can also conclude that is 1-valent. In other words, is bivalent.
we can also conclude that is 1-valent. In other words, is bivalent. - But and so
 A bivalent contradicts the initial assumption that has no bivalent configurations. Q.E.D.
A bivalent contradicts the initial assumption that has no bivalent configurations. Q.E.D.
Sub-lemma B.4 (“Commutativity property of schedules”): Suppose that from some configuration schedules  and
and  lead to configurations
lead to configurations  and
and  respectively, for some
respectively, for some  If the two sets of processors taking steps in and are disjoint, then the application of to and to will result in the same configuration
If the two sets of processors taking steps in and are disjoint, then the application of to and to will result in the same configuration  , for some
, for some 
Without loss of generality, suppose that the system’s processor set consists of two distinct processors  We will prove the sub-lemma for the simple case where the two schedules are disjoint singletons, i.e.,
We will prove the sub-lemma for the simple case where the two schedules are disjoint singletons, i.e.,  and
and  The general case can be analyzed using the same logic.
The general case can be analyzed using the same logic.
- Let be initially applied to The event
 corresponds to the receipt of message value
corresponds to the receipt of message value  by
by  Recall that the receive function deletes
Recall that the receive function deletes  from the message buffer and then depending on ‘s internal state and on the message value
from the message buffer and then depending on ‘s internal state and on the message value  enters a new internal state and sends a finite set of messages to other processors.
enters a new internal state and sends a finite set of messages to other processors. - Let

- At
 we can write:
we can write:




 ),
),
where is a set of newly generated messages and processors pairs.
- At
 we can write:
we can write:




 ),
),
where
is a set of newly generated messages and processors pairs.
- One can easily see that applying to and then applying to the resulting configuration would yield the same configuration

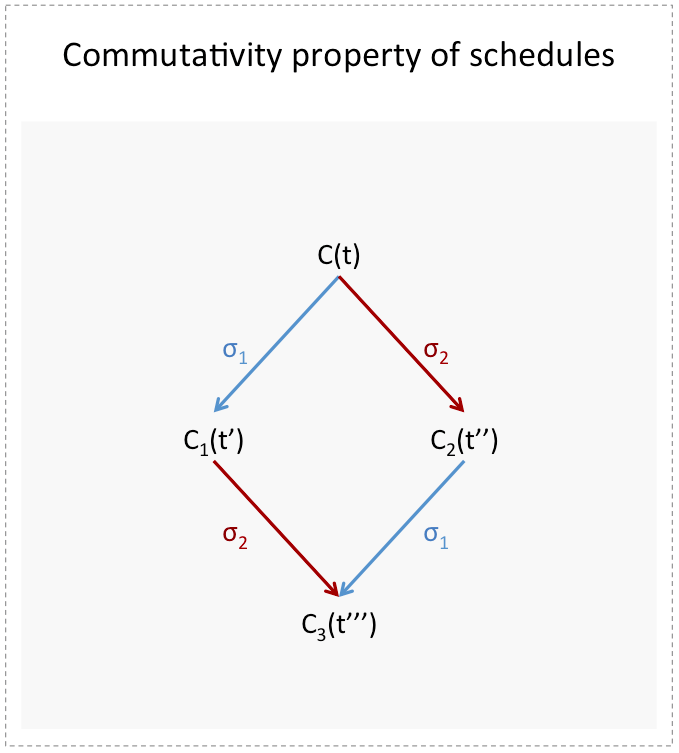
We are now in a position to prove Lemma B. Suppose that has no bivalent configurations. By Sub-lemma B.3, there must exist two neighboring configurations  such that
such that  is 0-valent and
is 0-valent and  is 1-valent ( is the event ). By virtue of being neighbors, we can assume without loss of generality that
is 1-valent ( is the event ). By virtue of being neighbors, we can assume without loss of generality that  for some event
for some event  We have two cases to consider:
We have two cases to consider:
- Case
 : We have
: We have  Since
Since  then the two processors taking steps in
then the two processors taking steps in  and
and  are disjoint. We can thus apply Sub-lemma B.4 to get
are disjoint. We can thus apply Sub-lemma B.4 to get  This is not possible since a 1-valent configuration cannot be reached from a 0-valent one.
This is not possible since a 1-valent configuration cannot be reached from a 0-valent one. - Case
 : Consider an admissible run starting at and such that processor is the only faulty process and such that it is assumed to have crashed prior to starting the run. By the total correctness assumption, this admissible run must also be a deciding one. Let be its corresponding schedule and let
: Consider an admissible run starting at and such that processor is the only faulty process and such that it is assumed to have crashed prior to starting the run. By the total correctness assumption, this admissible run must also be a deciding one. Let be its corresponding schedule and let  be the resulting configuration. Clearly, the set
be the resulting configuration. Clearly, the set  does not have any common processors with events included in
does not have any common processors with events included in  We can thus invoke Sub-lemma B.4 as portrayed in the diagram below:
We can thus invoke Sub-lemma B.4 as portrayed in the diagram below:
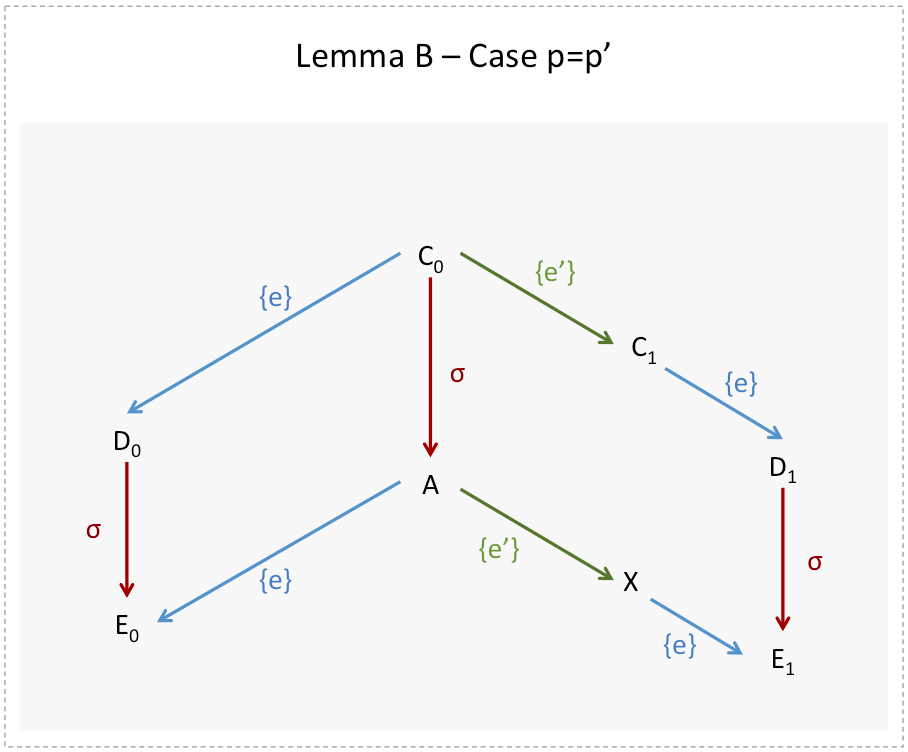
Since  is 0-valent, it must be that
is 0-valent, it must be that  is 0-valent too (we have previously shown as part of Lemma A that its decision set cannot be ). Similarly, since
is 0-valent too (we have previously shown as part of Lemma A that its decision set cannot be ). Similarly, since  is 1-valent, so must be Now note that and are both reachable from and have different valencies. must hence be bivalent. But is the outcome of a deciding run (by construction) and hence cannot be bivalent.
is 1-valent, so must be Now note that and are both reachable from and have different valencies. must hence be bivalent. But is the outcome of a deciding run (by construction) and hence cannot be bivalent.
In both cases we reached a contradiction, demonstrating that must contain at least one bivalent configuration.
In order to prove the FLP impossibility result, we now use Lemma A and Lemma B to build an admissible non-deciding run for any consensus protocol that is totally correct in spite of one fault. We first build a particular class of admissible runs as follows:
- Maintain a queue of processors, originally in arbitrary order.
- For any given configuration, let its associated message buffer be ordered according to the time the messages were sent, earliest first.
- Define a stage to be a collection of one or more steps. A stage is completed when the first processor in the queue takes a step. In this step, the processor receives the earliest message destined to it in the message buffer, or if no messages are available. The processor is then moved to the back of the queue.
Note that this construction ensures that in any infinite sequence of such stages, every non-faulty processor (i.e., one that can take infinitely many steps) will receive every message sent to it. Such a run is hence admissible. We now derive a particular instance of a non-deciding run that belongs to this class of admissible runs. Let be any bivalent initial configuration (its existence is guaranteed by Lemma A), and repeat the following procedure for each bivalent configuration 
- Let be the processor heading the processors queue at the time corresponding to configuration
 and the earliest message value destined to in the message buffer (if there is no such message, then
and the earliest message value destined to in the message buffer (if there is no such message, then  ). Let be the event
). Let be the event 
- Lemma B guarantees the existence of a bivalent configuration
 reachable from
reachable from  through the application of a schedule where is the last event applied.
through the application of a schedule where is the last event applied.
The previous procedure is actually an infinite loop characterizing an admissible run with no decision ever reached. Q.E.D.
Before we wrap up this chapter, we stress one more time the importance of defining clearly the system model attributes. For example, it suffices to substitute the deterministic nature of the Termination criterion with its randomized counterpart for the FLP result to stop holding as was proven in [1].
5. References
[1] Michael Ben-Or. Another advantage of free choice: Completely asynchronous agreement protocols. ACM, 1983.
[2] Cynthia Dwork and Nancy Lynch. Consensus in the presence of partial synchrony. Journal of the Association for Computing Machinery, 35(2):288-323, April 1988.
[3] Michael J. Fischer, Nancy Lynch, and Michael Merritt. Easy impossibility proofs for distributed consensus problems. ACM, 1985.
[4] Michael J. Fischer, Nancy Lynch, and Michael S. Paterson. Impossibility of distributed consensus with one faulty process. Journal of the Association for Computing Machinery, 32(2):374-382, April 1985.
[5] Leslie Lamport, Robert Shostak, and Marchall Pease. The byzantine generals problem. ACM Transactions on programming Languages and Systems, 4(3):382-401,July 1982.
[6] M. pease, R. Shostak, and L. Lamport. Reaching agreement in the presence of faults. Journal of the Association for Computing Machinery, 27(2):228-234, April 1980.
Tags: byzantine generals, consensus, FLP
No comments
Comments feed for this article
Trackback link: https://delfr.com/consensus-in-distributed-systems/trackback/